
Artificial intelligence (AI) is beginning to revolutionize a wide range of industries, most notably the automotive industry. While self-driving cars are making many headlines, most experts agree it will still be many years before human drivers are off the roads. In 2017 alone, NHTSA reported more than 37,000 people were killed in car crashes in the US. One of our goals at Nauto is to develop the next generation driver and fleet safety platform that can help save lives, today.
Distracted Driving Detection
Effective driver learning behavior platforms should detect whether a driver is paying attention to the road with very high accuracy. Traditionally, this task has been approached by engineering face and eye tracking algorithms. However, such algorithms often struggle given many challenging real-world conditions, including variable eye shapes, lighting conditions, accessories, occlusions and more. In recent years, deep learning has been the driving force behind dramatic improvements in many image classification and computer vision tasks. Commonly used in a supervised learning setup, deep learning models are trained using a large number of labels and training data. Data is key to producing highly accurate models. Nauto's growing network of connected cameras enables the targeted collection of large amounts of diverse, real-world data.
The Critical Role of Data
One of the first questions asked when approaching a machine learning project, is how much data do we need? How do we collect it and what are the labeling guidelines? In real-world applications, the success of a project often depends on the data as much as the choice of model or algorithm. This is especially true for problems such as real-time distracted driving detection, where variation in the data is high (as opposed to a stop sign detector, for example). At Nauto, our network of cameras has captured 150 million AI-processed video miles which helps pose an important question: what data should we collect and label? To be effective, we must use active learning methods.
With active learning, a relatively simple approach is to use a model to identify instances in which the prediction confidence is low. This is akin to a student (model) asking a teacher (human labeler) how to solve a problem he is not sure of. An additional consideration is to sample the data in a way that captures its diversity in an optimal way. Just as you wouldn't want to train a self-driving car with only data from circling the same block, you wouldn't want to bias your distracted driving detection model to any particular driver. We have found it very important to sample the data evenly across many different drivers.
Multi-Label Classification
General purpose eye and face tracking are hard problems, even for deep learning. How do you label the exact direction of the gaze, and what if sunglasses or a hat are covering the eyes? Synthetic data can be used, however it is challenging to generalize for drivers with different eye shapes, body postures, and camera positions. Given these challenges, we approach the problem as a simpler classification problem, where the classes are those relevant for real-time distracted driving detection. Classes such as "looking down", or "looking left/right" can be well defined, easily labeled, and used to train a deep neural network end-to-end. In addition, distracted driving detection should not be limited to just the gaze but should include additional indications of distraction, such as using a cell phone or manipulating the console. With multi-task learning, many different outputs can be predicted in parallel using a single neural network. In fact, the additional labels can help with overall training and improve the accuracy of other related labels.
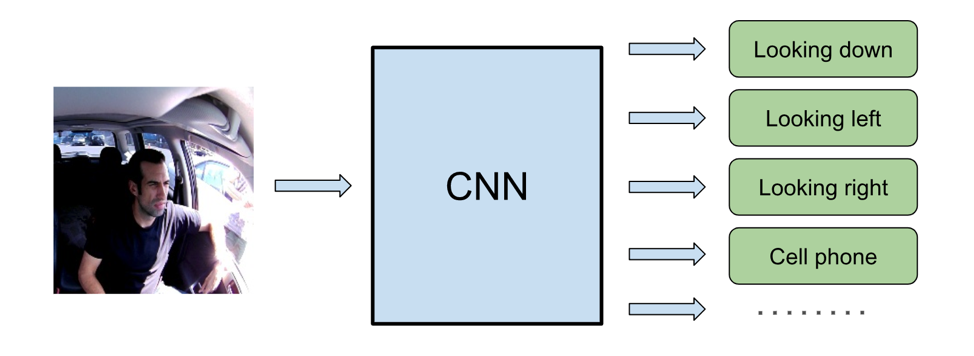
Learning Temporal Context
Intuitively, distracted driving is defined by actions over a period of time - a single frame provides limited information. Even a human labeler would most likely need to review frames from earlier in a video to establish a baseline. Some common deep neural networks for temporal modeling such as recurrent neural networks (RNN) and long short-term memory (LSTM) networks are successfully used in many applications today. Speech recognition is one notable application using audio signals. Applying these networks towards visual data, however, is more challenging, especially for real-time applications with limited computational resources.
A lesser-known network which can be used for embedding temporal information is the siamese network. The network allows to jointly train pairs of images using shared weights and predicting similarity between images. We can define similarity by the features that are most relevant for our learned task.
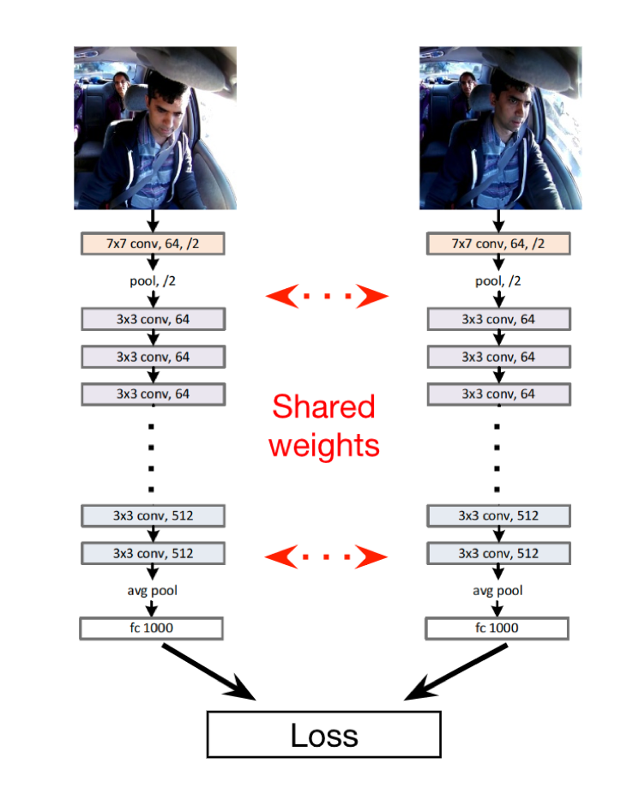
Given a baseline assumption that a driver is usually looking at the road while driving, we can pair a random reference frame during inference. Since almost all weights are shared in a siamese network setting, an output feature vector only requires being computed once. The result is minimal added computational overhead. Also, for improved robustness, we can average prediction results from pairing a set of multiple reference frames from the past. This approach can also be thought of as applying 1D convolutions of size 2 to N pairs of past reference frames. Our experiments show a comparable boost in accuracy using either LSTMs or the siamese network, with the siamese network approach being more computationally efficient and simpler to train.
The Road Ahead
Nauto's driver and fleet safety platform has been deployed since April 2017 and is helping coach and alert drivers, and making our roads safer everyday. With recent advancements in AI, we are able to achieve remarkable results. Still, there is much more to be done, and we are actively working on adding new capabilities, as well as improving overall accuracy, efficiency and driver experience. If you like solving complex problems that have a real-world impact and are excited to use AI to make our roads safer, please check out our careers page!

Related posts



Is Nauto right for your fleet?
Get in touch, we’ll answer questions or set up a demo.
